Exercices¶
Chute libre¶
Des étudiants ont effectués une expérience de chute libre: ils ont fait tomber un objet de chaque étage de l’Atrium, sans vitesse initiale, et ont mesuré à chaque fois le temps de chute \(T\) de l’objet ainsi que la hauteur de l’étage \(H\). On reporte dans le tableau ci-dessous le résultat des mesures pour 4 groupes différents.
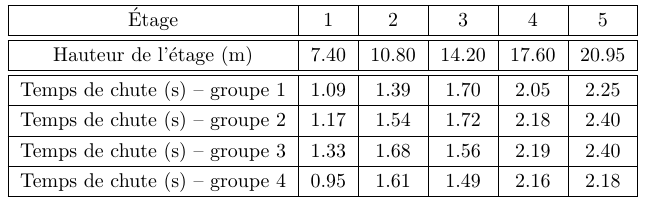
Nous savons que l’objet chute sous l’effet de la pesanteur. Nous voulons grâce à cette expérience déterminer la magnitude de la pesanteur. Pour cela, nous utilisons un modèle simple du temps de chute libre. On montre facilement d’après la loi fondamentale de la dynamique, si on néglige les frottements de l’air, le lien entre la hauteur de l’étage \(H\), le temps de chute \(T\), et la magnitude de la pesanteur \(g\):
- Identifier dans cette équation le(s) donnée(s) de l’expérience et le(s) paramètre(s) du modèle. Écrire les données sous la forme de tableaux numpy.
- Écrire le modèle sous la forme d’une fonction python à ajuster, de la forme \(y(x;a)=ax\).
- Déterminer la valeur de \(g\) en ajustant les données du 1er groupe. Afficher à l’écran la valeur trouvée, et faire un graphique sur lequel on voit le modèle (en ligne continue) et les données (marqueurs). On veillera à légender et mettre des titres aux axes et au graphique.
- Ajuster les données des 4 groupes grâce à une boucle, et calculer la valeur de \(g\) comme la moyenne des résultats des 4 groupes.
Correction¶
[1]:
import numpy as np
from scipy.optimize import curve_fit
import matplotlib.pyplot as plt
# Ecriture des données dans un tableau numpy
T = np.array([[1.09, 1.39, 1.70, 2.05, 2.25],
[1.17, 1.54, 1.72, 2.18, 2.40],
[1.33, 1.68, 1.56, 2.19, 2.40],
[0.95, 1.61, 1.49, 2.16, 2.18]])
H = np.array( [7.40, 10.80, 14.20, 17.60, 20.95])
# Modèle
def chute(x,a):
return a*x
# fit des données du 1er groupe
y = H
x = T[0,:]**2/2
params, covar = curve_fit(chute,x,y)
print("Groupe 1:")
print(" g = ", params[0], " m/s^2")
# Graphique
xm = np.linspace(0,3,100)
plt.plot(xm,chute(xm,params[0]))
plt.plot(x,y,'*')
plt.axis([0,3,0,25])
plt.legend(('Modèle','Données'))
plt.title('Fit des données du groupe 1')
plt.xlabel('T**2/2 [s**2]')
plt.ylabel('H [m]')
plt.show()
# fit des données de tous les groupes
Ng = 4
g = np.empty(4)
for i in range(4):
# fit des données du ieme groupe
y = H
x = T[i,:]**2/2
params, covar = curve_fit(chute,x,y)
print("Groupe ", str(i+1), ":")
print(" g = ", params[0], " m/s^2")
g[i] = params[0]
# Graphique
plt.plot(xm,chute(xm,params[0]))
plt.plot(x,y,'*')
plt.show()
print("Valeur Moyenne:")
print(" g = ", np.mean(g))
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
/tmp/ipykernel_1401/3326823884.py in <module>
1 import numpy as np
----> 2 from scipy.optimize import curve_fit
3 import matplotlib.pyplot as plt
4 # Ecriture des données dans un tableau numpy
5 T = np.array([[1.09, 1.39, 1.70, 2.05, 2.25],
ModuleNotFoundError: No module named 'scipy'
Loi de puissance¶
On va travailler sur les données des exoplanetes, déjà étudiées en 2eme semaine. Le but de l’exercice consiste à déterminer si les données expérimentales peuvent etre ajustées par la fonctioncorrespondant à la 3eme loi de Kepler.
- Charger les données des exoplanetes du fichier
exoplanets.datet representer \(\log(R)\) en fonction de \(\log(T)\) - Expliquer pourquoi la représentation graphique logarithmique est mieux adaptée que la représentation graphique linéaire.
- Montrer également (par le calcul) qu’il est possible de faire une régression linéaire en utilisant la représentation mathématique logarithmique pour ajuster la 3eme loi de Kepler.
Correction¶
[2]:
#1
import matplotlib.pyplot as plt
import numpy as np
import astropy.constants as cons
au = cons.au.value
s = 24*3600
d_exp = np.loadtxt('../etu-02-python-intermediaire/exoplanets.dat')
R = d_exp[:,0]*au
T = d_exp[:,1]*s
plt.figure()
lR = np.log(R)
lT = np.log(T)
plt.plot(lR,lT,'.')
plt.xlabel("$\log(R)$")
plt.ylabel("$\log(T)$")
plt.show()
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
/tmp/ipykernel_1401/2746358044.py in <module>
2 import matplotlib.pyplot as plt
3 import numpy as np
----> 4 import astropy.constants as cons
5 au = cons.au.value
6 s = 24*3600
ModuleNotFoundError: No module named 'astropy'
Question 2 L’échelle logarithmique permet de voir toutes les données dispersées sur plusieurs ordres de grandeur.
Question 3 De plus, si \(T^2 = k R^3\), alors \(\log(T) = \frac{3}{2} \log(R) + \frac{1}{2} \log(k)\)
==> On peut également tester la relation de proportionalité via un ajustement affine des distributions logarithmiques. On attend alors une pente de 1.5 et une ordonnée à l’origine égale à 0.5log(k).
[3]:
# 3
def reglin(xi, yi):
'''
Calcul les paramètres a,b du meilleur ajustement d'un modèle linéaire
y = ax + b sur un jeu de données (xi, yi)
'''
N = np.size(xi)
xm = np.mean(xi)
ym = np.mean(yi)
cov = 1/N * np.sum(xi*yi) - xm*ym
var = 1/N * np.sum(xi**2) - xm**2
a = cov / var
b = ym - a*xm
return (a,b)
# Modèle
def line(x,a,b):
return a*x+b
a,b = reglin(lR,lT)
print('a= ', a,' b= ',b)
k = np.exp(2*b)
print("k=",k,"kg/N/m2")
plt.figure()
x = np.linspace(min(lR),max(lR))
plt.plot(lR,lT,'.',x,a*x+b)
plt.xlabel("$\log(R)$")
plt.ylabel("$\log(T)$")
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
/tmp/ipykernel_1401/2207037755.py in <module>
21 return a*x+b
22
---> 23 a,b = reglin(lR,lT)
24 print('a= ', a,' b= ',b)
25 k = np.exp(2*b)
NameError: name 'lR' is not defined
Décroissance exponentielle¶
On va ici tenter de modéliser la vitesse de décroissance de l’épaisseur de mousse de bière. On reprendra pour cela les données présentées par Arnd Leike, chercheur à l’Université Ludwig Maximilians de Munich, dans une publication qui lui a valu le prix Ig Nobel en 2002.
Récupérer les données présentées dans le tableau 1 de la publication disponible au lien suivant: disponible ici: https://www.tf.uni-kiel.de/matwis/amat/iss/kap_2/articles/beer_article.pdf.
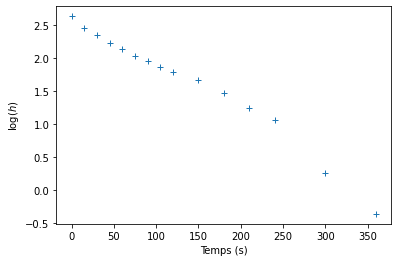
- Représentez le logarithme décimal de l’epaisseur de mousse de la Augustinerbräu en fonction du temps: \(\log_{10}(h) = f(t)\).
- Effectuez l’ajustement qui vous semble le plus approprié, et en déduire le modèle de décroissance auquel cet ajustement correspond. Déterminez le temps caractéristique de la décroissance
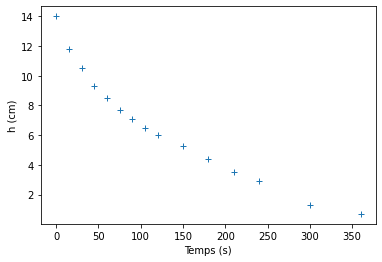
- Effectuer un ajustement exponentiel de la fonction \(h(t)\) (cf résultat ci-dessous), et comparez vos résultats à ceux de la question précédente.
- Le taux de désintégration d’un matériau radioactif suit également une loi exponentielle. Peut-on trouver une analogie avec l’épaisseur de la mousse de bière?
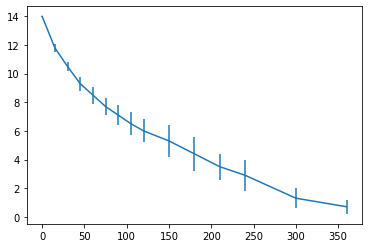
Dans le tableau 1 de l’article de Leike, l’auteur a également associé des incertitudes aux mesures d’épaisseur de mousses.
- Représentez ces incertitudes graphiquement en utilisant la fonction
errorbarde matplotlib (cf résultat ci-dessous).
Il est possible, dans l’ajustement d’un modèle \(y=f(x)\) aux données, de pondérer chaque mesure \(y_i\) par son incertitude \(\sigma_{yi}\). Pour se faire, on minimise en fait sur sa mesure dans l’ajustement la quantité appelée “Khi-2”, et définie par:
- Reprendre la question 3 en passant les erreurs \(\sigma_yi\) dans le paramètre sigma de la fonction
curve_fit. On veillera à remplacer les valeurs d’incertitudes nulles par une valeur > 0 pour permettre la convergence de l’ajustement (cf equation précédente).
On pourra remarquer qu’en plus des paramètres ajustés, un 2eme paramètre est retournée par la fonction curve_fit. Il s’agit de leur matrice de covariance de ces paramètres (que l’on peut noter pcov, dont on peut extraire l’incertitude sur chacun des paramètres, donnée par perr = np.sqrt(np.diag(pcov)).
Correction¶
[4]:
#1
# Données
h = np.array([14.0, 11.8, 10.5, 9.3, 8.5, 7.7, 7.1, 6.5, 6.0, 5.3, 4.4, 3.5, 2.9, 1.3, 0.7]) #cm
t = np.array([0, 15, 30, 45, 60, 75, 90, 105, 120, 150, 180, 210, 240, 300, 360]) #s
lh = np.log(h)
plt.plot(t,lh,'+')
plt.xlabel('Temps (s)')
plt.ylabel('$\log(h)$')
def modlin(x, a, b):
return a + b*x
# Ajustement linéaire
params, covar = curve_fit(modlin,t,lh,[14,-1])
print("(a,b)=",params)
print("tau=",-1/params[1],"s")
t_model = np.linspace(min(t),max(t))
y_model = params[0]+params[1]*t_model
plt.plot(t_model,y_model)
plt.show()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
/tmp/ipykernel_1401/2664501829.py in <module>
13
14 # Ajustement linéaire
---> 15 params, covar = curve_fit(modlin,t,lh,[14,-1])
16 print("(a,b)=",params)
17 print("tau=",-1/params[1],"s")
NameError: name 'curve_fit' is not defined
[5]:
#3.
def expLaw(x,A0,tau):
return A0*np.exp(-x/tau)
plt.plot(t,h,'+')
plt.xlabel('Temps (s)')
plt.ylabel('h (cm)')
params, covar = curve_fit(expLaw,t,h,[14,200])
print(params)
t_model = np.linspace(min(t),max(t))
y_model = params[0]*np.exp(-t_model/params[1])
plt.plot(t_model,y_model)
plt.show()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
/tmp/ipykernel_1401/4029386512.py in <module>
7 plt.ylabel('h (cm)')
8
----> 9 params, covar = curve_fit(expLaw,t,h,[14,200])
10 print(params)
11 t_model = np.linspace(min(t),max(t))
NameError: name 'curve_fit' is not defined
On remarquera que l’ajustements linéaire de \(log(h)\) et l’ajustement exponentiel de \(h\) produisent des valeurs différentes de la constante de temps \(\tau\) caractéristique de la décroissance déinie par \(y = e^{\frac{-t}{\tau}}\): 131 s contre 148 s.
[6]:
# Question 5
dh = np.array([0.01, 0.3, 0.3, 0.5, 0.6, 0.6, 0.7, 0.8, 0.8, 1.1, 1.2, 0.9, 1.1, 0.7, 0.5])
plt.errorbar(t,h,dh)
params, pcov = curve_fit(expLaw,t,h,[14,200],sigma=dh)
perr = np.sqrt(np.diag(pcov))
print(params)
print(perr)
print('Tau = ',params[1],'+-',perr[1],'s')
t_model = np.linspace(min(t),max(t))
y_model = params[0]*np.exp(-t_model/params[1])
plt.plot(t_model,y_model)
plt.xlabel('Temps (s)')
plt.ylabel('h (cm)')
plt.show()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
/tmp/ipykernel_1401/1681192833.py in <module>
4
5 plt.errorbar(t,h,dh)
----> 6 params, pcov = curve_fit(expLaw,t,h,[14,200],sigma=dh)
7 perr = np.sqrt(np.diag(pcov))
8 print(params)
NameError: name 'curve_fit' is not defined
Ajustement sinusoidal¶
On va maintenant travailler sur mes mesures de température effectué à la station météorolgique de Montélimar, qui serviront également pour le mini-projet. Ces données sont disponibles sur le site https://www.ecad.eu/.
- Chargez et représentez les températures quotidiennes sur la décennie 1970.
- On observe très clairement des fluctuations saisonnières dans ces données. Proposez un ajustement pour les modéliser et réalisez le.
Remarques
Il est conseillé d’utiliser des variables de type numpy.datetime64 pour manipuler les dates.
Suivant la version de matplotlib que vous utilisez, il est cependant possible que vous ayez des problèmes pour représenter ce type de variables. On pourra alors choisir de les transformer en variables réelles, en utilisant la commande astype(float).
Correction¶
[7]:
import numpy as np
import matplotlib.pyplot as plt
# Récupération des données
a = np.loadtxt('ECA_blended_custom/TG_STAID000786.txt',skiprows = 20,delimiter=',')
station_id = a[:,0]
date = a[:,1]
T = a[:,2]/10
Q = a[:,3] # facteur de qualité
# Use valid data only
date = date[Q == 0]
T = T[Q == 0]
# Construction de la variable de temps
dt = []
for d in date:
Y = str(d)[0:4]
M = str(d)[4:6]
d = str(d)[6:8]
#print(Y,M,d)
dt.append(np.datetime64(Y+'-'+M+'-'+d))
dt = np.array(dt) # On enregistre les variables d etemps comme un numpy.array de datetime64.
print("Il y a",len(T)," mesures de température dans ce fichier entre",min(dt),",et",max(dt))
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
/tmp/ipykernel_1401/3859740807.py in <module>
3
4 # Récupération des données
----> 5 a = np.loadtxt('ECA_blended_custom/TG_STAID000786.txt',skiprows = 20,delimiter=',')
6 station_id = a[:,0]
7 date = a[:,1]
~/checkouts/readthedocs.org/user_builds/phys-mod/envs/2020.1/lib/python3.7/site-packages/numpy/lib/npyio.py in loadtxt(fname, dtype, comments, delimiter, converters, skiprows, usecols, unpack, ndmin, encoding, max_rows, like)
1065 fname = os_fspath(fname)
1066 if _is_string_like(fname):
-> 1067 fh = np.lib._datasource.open(fname, 'rt', encoding=encoding)
1068 fencoding = getattr(fh, 'encoding', 'latin1')
1069 fh = iter(fh)
~/checkouts/readthedocs.org/user_builds/phys-mod/envs/2020.1/lib/python3.7/site-packages/numpy/lib/_datasource.py in open(path, mode, destpath, encoding, newline)
191
192 ds = DataSource(destpath)
--> 193 return ds.open(path, mode, encoding=encoding, newline=newline)
194
195
~/checkouts/readthedocs.org/user_builds/phys-mod/envs/2020.1/lib/python3.7/site-packages/numpy/lib/_datasource.py in open(self, path, mode, encoding, newline)
531 encoding=encoding, newline=newline)
532 else:
--> 533 raise IOError("%s not found." % path)
534
535
OSError: ECA_blended_custom/TG_STAID000786.txt not found.
[8]:
# Représentation
sel = np.logical_and(dt>np.datetime64('1970-01'),dt<np.datetime64('1980-01'))
dt1970 = dt[sel]
dtf1970 = dt1970.astype(float)
T1970 = T[sel]
plt.figure()
plt.plot(dt1970,T1970)
plt.xlabel('Date')
plt.ylabel('T')
plt.xlim(min(dt1970),max(dt1970))
# Ajustement sinusoidal
def sinLaw(x,a,T0,phi,c):
w = 2*np.pi/T0
return a*np.sin(w*x+phi)+c
params, covar = curve_fit(sinLaw,dt1970,T1970,[10,365,0,np.mean(T)])
perr = np.sqrt(np.diag(covar))
# Attention: pour calculer la fonction, on doit utiliser un tableau de réels plutot que de datetime64
y_model = params[0]*np.sin(2*np.pi/params[1]*dtf1970+params[2])+params[3]
plt.plot(dt1970,y_model)
print(params)
print(perr)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
/tmp/ipykernel_1401/2998996002.py in <module>
1 # Représentation
----> 2 sel = np.logical_and(dt>np.datetime64('1970-01'),dt<np.datetime64('1980-01'))
3
4 dt1970 = dt[sel]
5 dtf1970 = dt1970.astype(float)
NameError: name 'dt' is not defined